
정보처리기사 정리 - SW 개발
SW 개발
자료구조
자료구조의 분류
- 선형 구조 : 선형리스트(배열), 연결리스트, 스텍, 큐, 데크
- 비선형 구조 : 트리, 그래프
연결리스트
- 자료를 임의의 기억공간에 기억시키되, 자료 순서에 따른 노드 포인터 부분이용해 연결
- 노드의 삽입, 삭제가 쉬우나 연결을 위한 포인터 부분이 필요해 기억공간 활용 불리, 속도 낮음
- 기억공간이 연속적이지 않아도 저장 가능
- 희소행렬로 기억장소 절약 가능
- 트리 표현하기 적합
- 시간 복잡도 $O(n)$
스텍(Stack)
- 리스트의 한쪽 끝으로만 자료의 삽입 삭제 작업이 이루어짐, 순환적 프로그램 사용시 사용
- Last in Last Out(LIFO)
- TOP: Stack의 가장 마지막에 저장된 자료가 기억된 위치(스텍 포인터)
- Botton: 스텍의 가장 밑 바닥
- Push : Stack 에 데이터 삽입
- Overflow: 스텍의 모든 기억장소가 꽉채워져 있는 상태로 더 이상 자료 삽입 불가
- Pop : Stack에 데이터 삭제
- Underflow: 스텍 포인터 값이 ‘0’ 이되면 더이상 삭제할 자료 가 없음
큐(Queue)
- 선형리스트 구조로 한쪽에서는 삽입 다른 쪽에서는 삭제 작업이 일어나는 자료구조
- First In First Out(FIFO)
- 사작과 끝을 표현하는 2개의 포인터를 갖음
데크(Deque)
- 삽입과 삭제가 양쪽 끝에서 가능한 자료 구조 Stack과 Queue의 장점을 가져와 구성
트리(Tree)
정점 노드와 선분을 이용하여 사이클을 이루지 않고 구성한 그래프의 일종
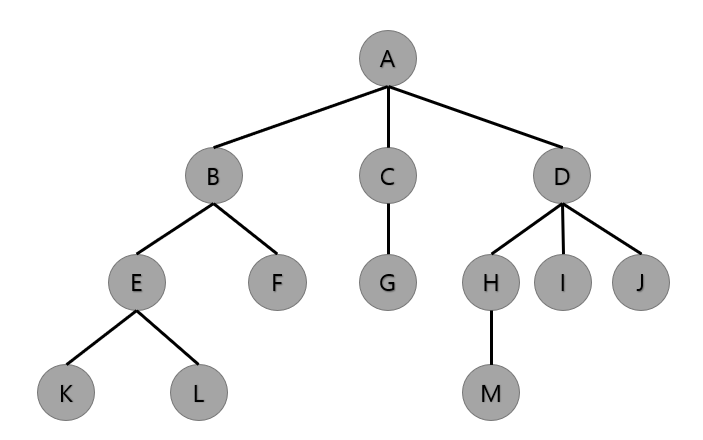
- 노드 : 트리의 기본요소 (A~M)
- 근노드 : 트리 맨 위에 있는 노드 (A)
- 디그리 : 각 노드에서 뻗어 나온 가지 수(A = 3, B = 2 …)
- 트리의 디그리 : 노드들의 디그리 중 가장 많은 수 (3)
- 단말노드(leaf Node) : 자식이 없는 노드, 즉 디그리가 0 인 노드(K, L, F, G, M, I, J)
- 비 단말노드 : 자식이 하나라도 있는 노드(A, B, C, D, E, H)
- 자식 노드 : 어떤 노드에 연결된 다음 레벨의 노드(D의 자식 = H, I, J)
- 부모 노드 : 어떤 노드에 연결된 이전 레벨의 노드(E, F의 부모 = B)
- 형제 노드 : 동일한 부모를 가진 노드(H의 형제 노드 = I, J)
- Level : 근 노드를 Level 1로 가정해 다음 자식부터 + 1
- 깊이(Depth) : 어떤 트리에서 노드가 가질 수 있는 최대 Level(4)
이진 트리
무조건 왼쪽부터 차례대로 넣는 트리 구조를 이진 트리라 한다.
- 이진트리의 운행법
- 전위(PreOrder) 운행 : Root - Left - Right
- 중위(InOrder) 운행 : Left - Root - Right
- 후위(PostOrder) 운행 : Left - Right - Root
힙
데이터에서 최대값과 최소값을 빠르게 찾기 위해 고안된 완전 이진 트리 최대 힙과 최소 힙이 있음 시간 복잡도 : $O(logn)$
정렬
정렬은 파일을 구성한느 각 레코드들을 측정 키 항목 기준으로 오름차순, 내림차순으로 재 배열하는 방식
- 삽입 정렬 : $O(n^2)$
- 버블 정렬 : 반복문이 2개 이기 떄문에 $O(n^2)$
- 선택 정렬 : 주어진 데이터중 가장 작은 값 찾아 맨앞으로 끌고옴 $O(n^2)$
- 퀵 정렬 : 기준점(Pivot)을 정해서 기준점보다 작은 데이터는 왼쪽 큰 것은 오른쪽으로 모음, 재귀함수를 사용하여 동일함수 반복적으로 수행 $O(nlogn)$
- 병합 정렬 : 리스트를 절반으로 잘라 두 부분을 재귀함수를 통해 반복적으로 비교 $O(nlogn)$
탐색
- 순차 탐색 : 원하는 데이터를 앞에서부터 하나씩 탐색 $O(n)$
- 이진 탐색 : 탐색할 자료를 둘로 나누어 해당 데이터가 있을만한 곳을 탐색하는 방법 $O(logn)$ 최악의 경우 링크드 리스트와 동일한 $O(n)$
- 그래프
- BFS(Breadth First Search: 너비우선탐색) : $O(V(노드수) + E(간선수))$
- DFS(Depth First Search: 깊이우선탐색) : $O(V(노드수) + E(간선수))$
DRM(디지털 저작권 관리)
- 클리어링 하우스 : 권한정책 라이선스
- 콘텐츠 제공자 : 패키지, 콘텐츠, 메타데이터
- 콘텐츠 분배자 : 유통 시스템
- 콘텐츠 소비자 : DRM 컨트롤러, 보안 컨테이너
SW 형상관리
- SW 버전 등록 주요 언어
- 저장소(Repository) : 최신 버전의 파일들과 변경 내역에 대한 정보들이 저장되어 있는 곳
- 가저오기(Import) : 버전관리가 되고 있지 않은 아무것도 없는 저장소에 처음으로 파일 복사
- 체크아웃(Check-Out) : 프로그램 수정하기 위해 저장소에서 파일을 받아온다.
- 체크 인(Check-In) : 체크아웃 한 파일의 수정을 완료한 후 저장소에 처음으로 파일을 복사한다.
- 커밋(Commit) : 체크인을 수행할 때 이전에 갱신된 내용이 있는 경우 충돌을 알리고 diff 도구를 이용해 수정한 후 갱신을 완료한다.
- 동기화(Update) : 저장소에 있는 최신 버전으로 자신의 작업 공간을 동기화
- SW 버전 등록 과정
- Import - Chekout(인출) - Commit(예치) - Update(동기화) - Diff(차이)
테스트 기법에 따른 APP 테스트
- 화이트 박스 테스트 : 기초 경로 검사, 제어 구조 검사
- 블랙 박스 테스트 : 동치 분할 검사, 경계값 분석, 원인-효과 그래프, 오류 예측 검사, 비교 검사
개발 단계에 따른 APP 테스트
- SW 개발 단계 : 요구사항 - 분석 - 설계 - 구현
- 테스트 단계 : 단위테스트 - 통합테스트 - 시스템테스트 - 인수테스트
- 통합테스트 :
- 하향식 통합 테스트 : Stub
- 상향식 통합 테스트 : Driver
- Test Oracle : 맞는지 확인하기 위해 사전에 정의한 참인 값을 대입해서 테스트